We must ensure that our AI Systems are not biased. This can be an issue when building Deep Learning models from a biased training set.
Advances in AI technology have enabled a large number of successful applications, especially in the area of Deep Learning. But the issue of learned bias has raised its ugly head and must be addressed. The good news is that the AI research community has been working on this problem and interesting and effective solutions are being developed.
There are many different types of biases. Here are some examples.
Gender bias
Economic bias
Racial bias
Sexual orientation bias
Age bias
If we train our AI systems from biased data, these biases will be learned. For example, if we train a Deep Learning system on images of doctors and an overwhelming percentage of the images are of male doctors, the system is likely to learn that doctors are men. In their 2016 paper, “Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings,” Tolga Bolukbasi, et al. showed a disturbing level of gender bias in word embeddings trained from Google News articles. But they also proposed an effective way of removing this bias from the models that are learned. The basic idea is to change the embeddings of gender neutral words, by removing their gender associations. The same approach can be taken for other forms of bias.
The fact that we have this problem to deal with in Machine Learning sheds a light on the extensive amount of bias that exists in the human world and unfortunately, it seems easier to fix the bias issue in AI systems than in humans.
“Debiasing humans is harder than debiasing AI systems.” – Olga Russakovsky, Princeton
A grammar for parking signs can be used in conjunction with image recognition and text recognition to reason when parking is permitted and for how long.
Street parking in Los Angeles can be a nightmare. Besides the lack of available spaces, signage can be complex and confusing. Often there are multiple signs posted on the same pole that must be read, understood, and reasoned over in order to avoid a citation or towing (the signs in the image at the top of this post are typical). Fortunately, parking sign understanding can be automated with Artificial Intelligence techniques such as image recognition, text recognition, and machine learning. This post describes one piece of a comprehensive solution – a grammar for parking signs – that can be used to generate parsers that apply rules to unstructured sign text to facilitate automated reasoning. I will also show how ANTLR can be be used to generate a parser from the grammar. Grammar for LA parking signs and example photos can be found here on GitHub.
Grammar in this context is defined as the way that we expect words to be arranged on parking signs (for now, we ignore non-alphanumeric symbols such as a P with a line through it). A useful grammar notion commonly used in Computer Science is Extended Backus-Naur form (EBNF).
No Parking for Street Sweeping
One common sign found in Los Angeles and the source of many citations is no parking when there is street sweeping. Several instances of this sign are shown below. Note the following variations:
“NO PARKING” text versus the symbol P with a red circle and line through it
The time range specified by “TO” versus a dash “-“
“12NOON” instead of “12PM”
“STREET SWEEPING” versus “STREET CLEANING”
I wrote a program using Apple’s Vision Framework to process these images and extract text from them. The output for these four signs (clockwise from top left) is as follows (note that the output is always uppercase):
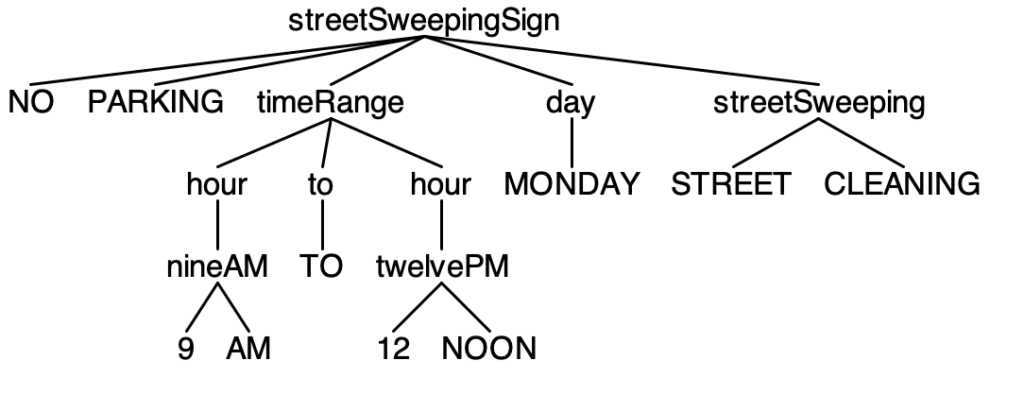
NO PARKING 9AM TO 12 NOON MONDAY STREET CLEANING
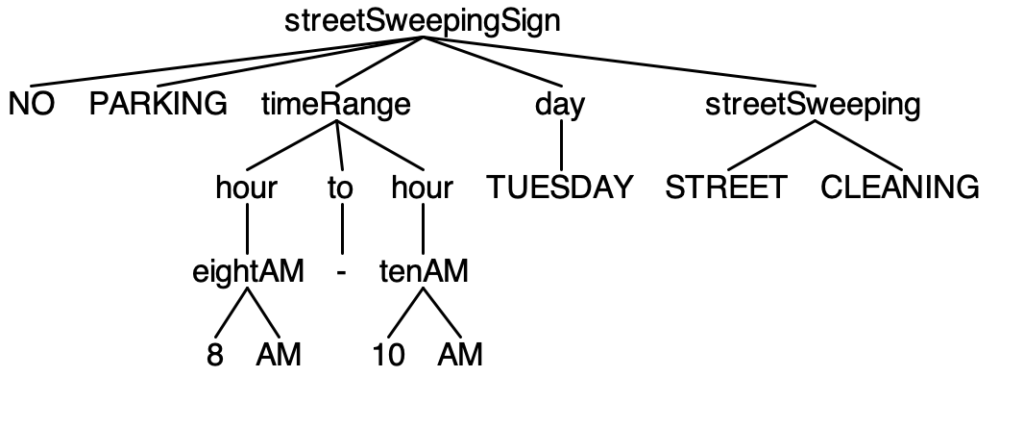
NO PARKING 8AM – 10AM TUESDAY STREET CLEANING
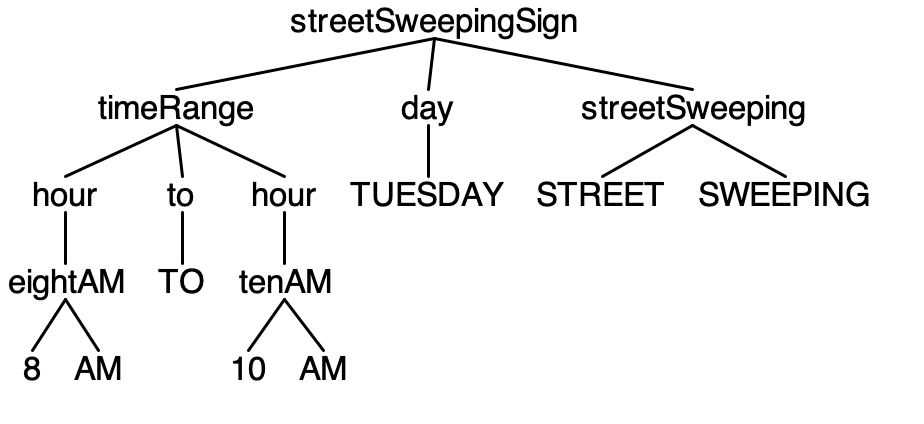
8AM TO 10 AM TUESDAY STREET SWEEPING
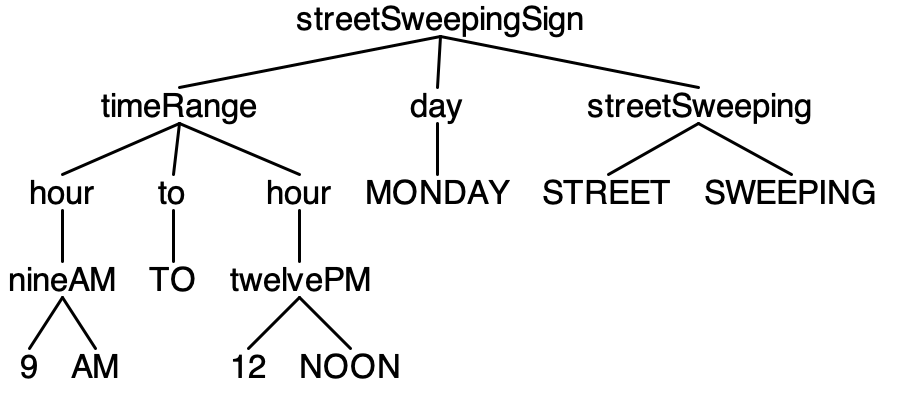
9AM TO 12NOON MONDAY STREET SWEEPING
EBNF Grammar
We would like a grammar that covers all of these variations, can be used to distinguish street sweeping signs from other signs, and allow us to understand the parking rules on this street. Taking a bottom-up approach, note that “STREET SWEEPING” and “STREET CLEANING” really mean the same thing, so we can create an EBNF grammar rule for them as follows.
streetSweeping : STREET ( SWEEPING | CLEANING ) ;
The vertical line between SWEEPING and CLEANING means that either of these tokens can match. So if a parser finds the text “STREET SWEEPING” or “STREET CLEANING,” this grammar rule would be executed and create a “streetSweeping” node in the parse tree with the matching tokens as child nodes.
The part of the Parser that matches input text to tokens is called the Lexer. Our grammar would need three lexical rules to support the “streetSweeping” rule as follows.
The characters between the single quote marks are matched one for one with the input text from the sign and if there is a match, the Lexer creates a node in the parse tree corresponding to the word.
We apply the same approach to identifying the time range on the signs. Some signs specify the range in the form 8AM TO 10AM and others as 8 TO 10AM so we have different rules for “time” and just a plain integer.
timeRange : (time to time) | (INT to time) ;
Since the signs have three conventions for indicating time range (“TO” “THRU” and “-“), we can have a grammar rule for this as well, along with lexical rules to support it.
to : TO | THRU | DASH ;
TO : 'TO' ;
THRU : 'THRU' ;
DASH : '-' ;
For the hours in the time range, we need to handle AM/PM and also NOON and MIDNIGHT. We also need to be able to handle the case when there is a space between the hour number and the AM/PM/NOON/MIDNIGHT and when there is no space (the output of the text recognition software is inconsistent here).
The top-level EBNF grammar rule for street sweeping signs can be written as:
streetSweepingSign
: NO? PARKING? timeRange day streetSweeping
;
The question marks after “NO” and “PARKING” mean that these are optional. That is all the grammar to support this one type of sign. Many of these rules can be reused for other signs (e.g., day, timeRange).
Generating a Parser from the Grammar
ANTLR is a powerful parser generator that operates on an input grammar file to generate all the source code files you need in a target language that can be incorporated into the rest of your application. It also provides command line tools to test your grammar against input text streams. Running the parser generated from the Street Sweeping Sign grammar against the four sign instances creates the following parse trees.
NO PARKING 9AM TO 12 NOON MONDAY STREET CLEANING
NO PARKING 8AM – 10AM TUESDAY STREET CLEANING.
8AM TO 10 AM TUESDAY STREET SWEEPING.
9AM TO 12NOON MONDAY STREET SWEEPING.
Other Types of Parking Signs
There are other types of parking signs that can be found in Los Angeles. The grammar described here for street sweeping signs has been extended to cover all of the instances I’ve encountered (I haven’t driven on every street in LA yet!). This comprehensive parking sign grammar and parser can be used to identify multiple parking signs and reason about whether it is safe to park and for how long. That app is under development and could be the subject of a future post.